[wpdm_package id=’5662′]
[wpdm_package id=’5656′]
import pandas as pd
df = pd.read_csv("./klassifizierung.csv")
# Wenn du ein paar Spalten vorab aus den Daten entfernen
# df = df.drop("Spaltenname", axis = 1)
# Wenn du eine kategorische Variable in mehrere Spalten umwandeln
# möchtest, kannst du das mit folgendem Code tun:
# df = pd.get_dummies(df, columns = ["Spaltenname"])
df.head()from sklearn.model_selection import train_test_split
# Welche Spalten sollen zur Vorhersage verwendet werden
X = df[["Alter", "Interesse"]].values
# Oder: Die Spalte "Erfolg" soll nicht zur Vorhersage verwendet werden:
# X = df.drop("Erfolg", axis = 1).values
y = df["Erfolg"].values
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0, test_size = 0.25)#from sklearn.preprocessing import StandardScaler
#scaler = StandardScaler()
#scaler.fit(X_train)
#X_train = scaler.transform(X_train)
#X_test = scaler.transform(X_test)from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(criterion = "entropy")
model.fit(X_train, y_train)
print(model.score(X_test, y_test))Ergebnis: 0.946666666667
# Hinweis: Damit dieser Befehl funktioniert, muss die
# "helper.py" - Datei im selben Ordner liegen, wie das
# aktuelle Jupyter Notebook
from helper import plot_classifier
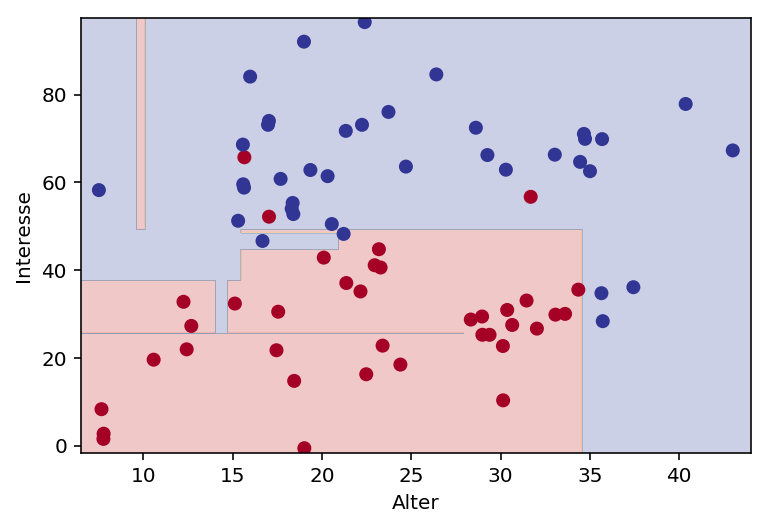
# Trainings-Daten plotten
plot_classifier(model, X_train, y_train, proba = False, xlabel = "Alter", ylabel = "Interesse")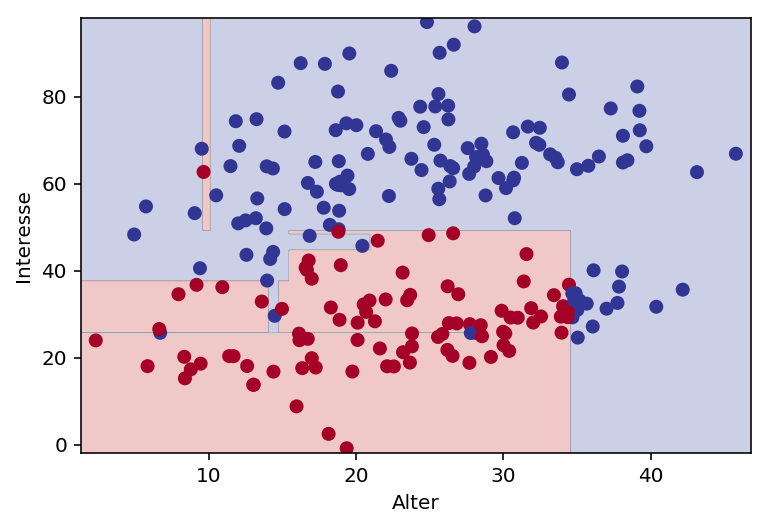
# Testdaten plotten
plot_classifier(model, X_test, y_test, proba = False, xlabel = "Alter", ylabel = "Interesse")