#Import
import pandas as pd
df = pd.read_csv("./mega_proeinkauf.csv")
#Spalten Eliminieren via
#df = df.drop("Spaltenname", axis = 1)
#Umwandlung von kategorischen Variablen in mehrere Spalten
#df = pd.get_dummies(df, columns = ["Spaltenname"])
df.head()
#Test- und Trainingsdatensplit
from sklearn.model_selection import train_test_split
X = df[["DIKEp", "Price"]].values
#neue Variante: nimm alles, was da ist, ausser X = df.frop("success", axis =1).values
y = df["shop.aestetics"].values #für das visualisieren ist es besser, wenn statt beliebigen String 0,1 steht.
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0, test_size=.25)
#Skalieren
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
## Anfang MLM
# KNN
from sklearn.neighbors import KNeighborsClassifier
model_k = KNeighborsClassifier(n_neighbors = 5)
# n_neighbors bestimmt, wieviele Nachbarn berücksichtigt werden
# default 5
model_k.fit(X_train, y_train)
print(model_k.score(X_test, y_test))0.6966292134831461
#Logistic Regression
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
print(model.score(X_test, y_test))0.7191011235955056
# Plotten mit helper.py
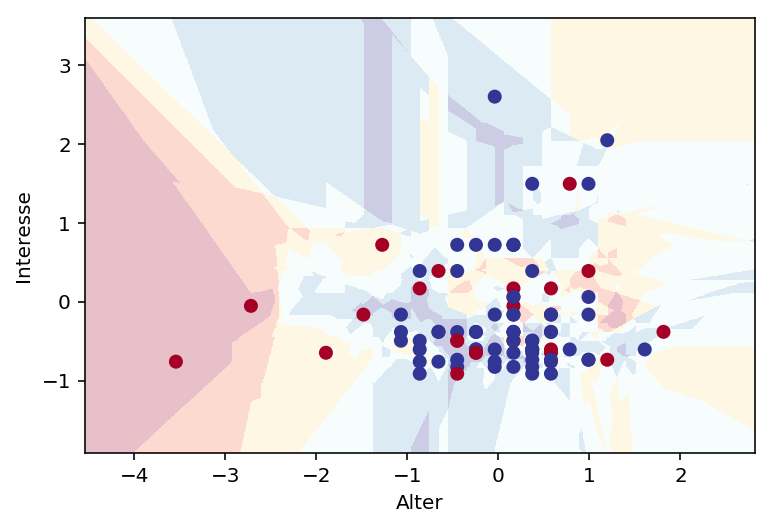
from helper import plot_classifier
plot_classifier(model_k, X_train, y_train, proba=True, xlabel = "Preis", ylabel="positive emotions")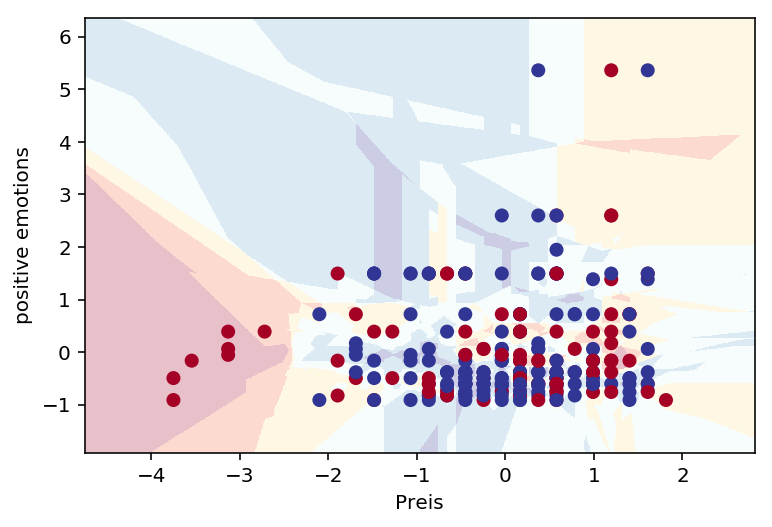
# Plotten mit Testdaten
plot_classifier(model_k, X_test, y_test, proba=True, xlabel = "Alter", ylabel="Interesse")